

Any analytics project today requires data integration, cleansing, manipulation and often they require machine learning. In order to solve these problems a hodge podge of tooling is typically required. That usually leads to glueing technologies together that were never meant to really work with each other in the same place. The problem is exacerbated when machine learning is involved because deploying machine learning projects often involves moving the work from the team that developed the model to a team that allows its results to be consumed.
KNIME has been a promising platform for our team over the past several years to coordinate these heterogenous activities. It supports in one place data integration, cleansing, manipulation and is a tremendous machine learning workbench. Over the past two days KNIME Summit 2017 was held here in Austin, TX and I got to attend and hear about what was going on with this platform.
They continue to push the features on guided analytics forward. Now they allow filtering and parameterization of workflows so that highly technical machine learning resources can punch out their work in a workflow that can be provided to business analysts, who then can filter and manipulate data to see the effect on the output the expert created. This extends KNIME’s ability get different skill sets using different tools to be productive in the same analytics project. Business analysts can be empowered to play with the machine learning solutions as well and make it work better, whether it is applying new business rules to the data or even excluding records that they know don’t make sense.

Andres Zijlstra discusses predictions on patient outcome using KNIME
KNIME’s commitment to open source also remains strong. Having taken on a €20M investment, one would imagine they are starting to feel the pressure of monetizing their platform more extensively. However, their investment partner Invus seems to be allowing them to play the long game and provide a valuable open platform first, with monetization being a secondary and longer term consideration. The value to those who use KNIME seems quite impressive, an open source platform that does not require the technical specialization of a Hadoop deployment that has an active enough community contributing to get the latest machine learning techniques baked in.

While one does not have to be a Hadoop specialist, KNIME still provides big data capabilities on Hadoop with Cloudera, Hortonworks and MapR all acknowledging the platform’s integration. KNIME’s big data connectors provide the ability to pull data from big data sources, and more importantly execute workflows on them. That means KNIME can actually push the heavy lifting in its workflows down to the big data tool and simply make the result available to the person consuming the data. This could become the next big interface to SPARK which has developed a reputation for being extraordinarily difficult to deploy and maintain, even after you account for the tremendous expense of those skilled in Spark to staff it. KNIME will soon offer the ability to spin up a large cluster in the cloud, perform the defined jobs in the cloud and then collect the results to visualize or deploy a model’s benefit to consumers.
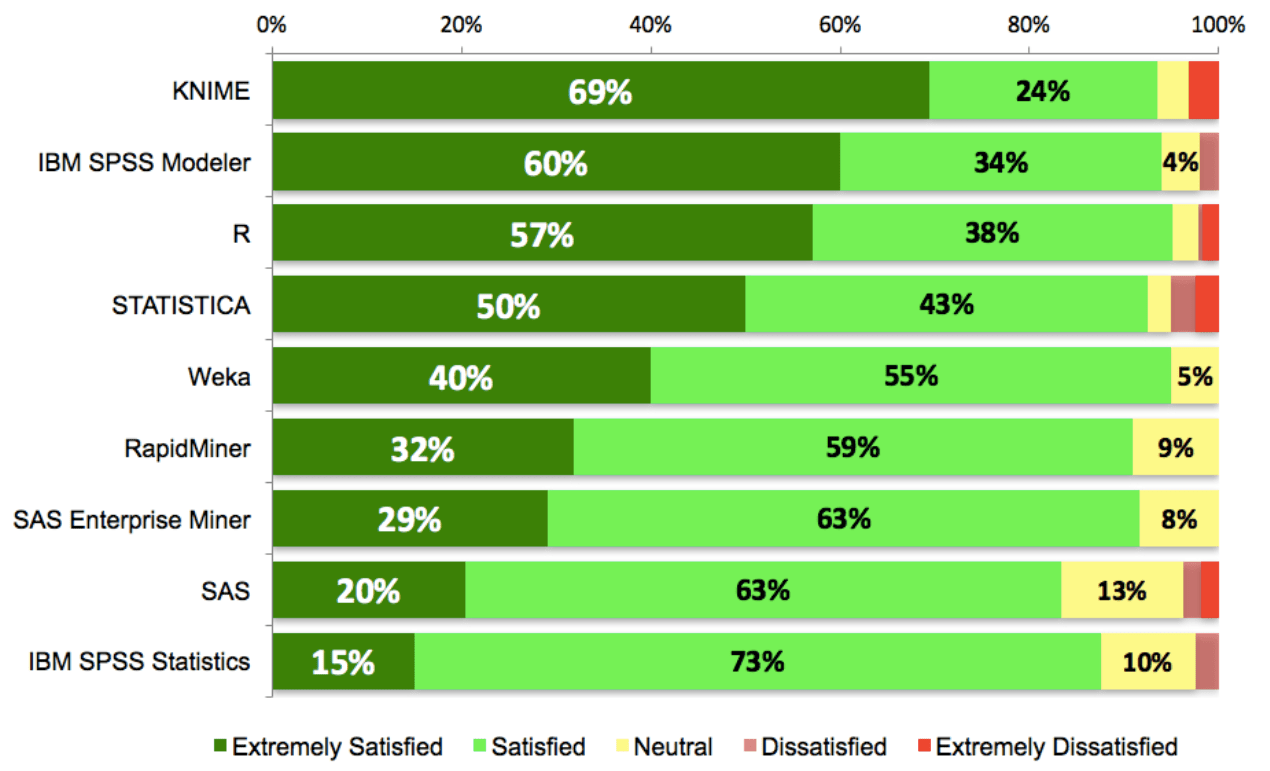
Rexer’s annual data mining survey ranks KNIME very highly, over many options that are closed solutions, on user satisfaction.
The tools still remains one of the most satisfying for customers according to surveys. Rexer publishes annual survey amongst analytics and data mining practitioners, has illustrated how high the satisfaction is when compared to other tools. At Blacklight, we had our concerns initially on performance as KNIME stages information to disk in between operations requiring both a disk write and the information to be persisted. That exploded the amount of storage a workflow requires while also slowing it down on throughput. However, the proliferation of SSD’s, expansion of cheap storage and the new abilities to push work to tools meant for heavy lifting bring the potential for open source high scale analytics to most organizations.



{kind=link}
{kind=link}
{kind=link}